트랜스포머(Transformer)
2017년 NeurIPS 논문에 등장한 Transformer model은 여러 NLP 작업에서 seq2seq 모델의 성능을 능가한다고 알려졌다.
입력과 출력 시퀀스 사이에 있는 전역 의존성(global dependency)을 모델링 할 수 있다.
트랜스포머 모델의 구조는 어텐션(attention)이라는 개념을 기반으로 한다.
셀프 어텐션 메커니즘(self-attention mechanism)을 기반으로 한다.
셀프 어텐션 메커니즘(self-attention mechanism)
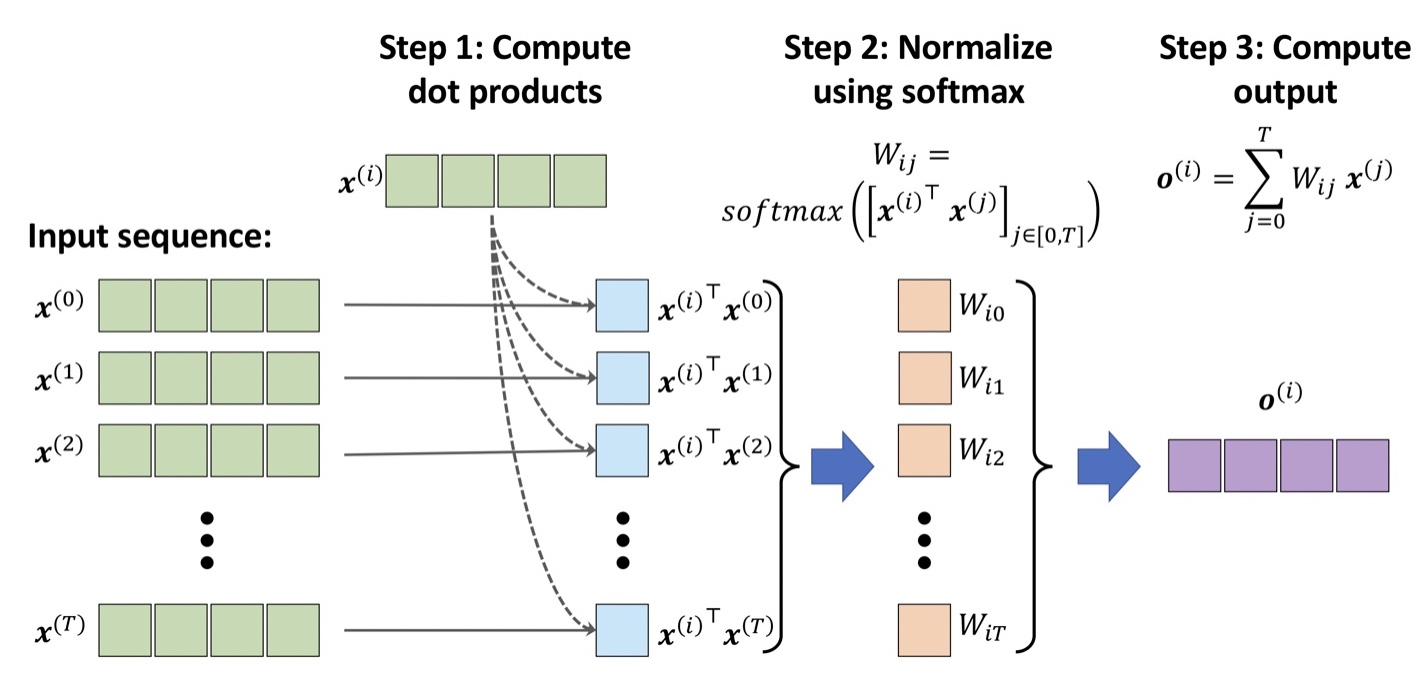
길이가 T인 입력과 출력 시퀀스를 가정할 때, 시퀀스의 각 원소의 x_t, o_t의 크기는 d인 벡터이다.
seq2seq 작업에서 셀프 어텐션은 입력 원소에 대한 출력 시퀀스에 있는 각 의존성을 모델링하는 것이 목적이다.
1. 현재 원소와 시퀀스에 있는 다른 모든 원소 사이의 유사도를 기반으로 중요도 가중치를 계산한다.
2. 소프트맥스 함수를 사용하여 가중치를 정규화한다.
3. 가중치를 해당하는 시퀀스 원소와 결합하여 어텐션 값을 계산한다.
쿼리, 키, 값 가중치(셀프 어텐션 메커니즘 in 트랜스포머)
트랜스포머에서는 셀프 어텐션 메커니즘을 개량하여 사용한다.(고급 셀프 어텐션 메커니즘)
기본적인 셀프 어텐션 메커니즘은 출력을 계산할 때, 학습되는 파라미터를 전혀 사용하지 않는다.
즉, 기본적인 셀프 어텐션 매커니즘을 사용하면 트랜스포머 모델이 주어진 시퀀스를 학습하는 동안 모델을 최적화하거나,
어텐션 값을 바꾸거나 업데이트를 하는데 제한적이다.
셀프 어텐션 메커니즘이 모델 최적화에 대해 유연하고 적응할 수 있게 만들기 위해서 추가적인 가중치 행렬을 사용한다.
(모델이 훈련하는 동안 학습되는 파라미터)
각각의 가중치들은 쿼리 시퀀스, 키 시퀀스, 값 시퀀스를 만들기 위해 사용
 Uq, Uk, Uv가 가중치 행렬들이다.
Uq, Uk, Uv가 가중치 행렬들이다.입력 시퀀스 원소와 j번째 시퀀스 원소 사이의 점곱으로 정규화되지 않은 가중치 대신에,
쿼리와 키 사이에 점곱을 계산한다.(이후 소프트맥스 함수로 가중치를 정규화하기 전에 스케일 조정)
멀티-헤드 어텐션(Multi-Head Attention, MHA)
여러 개의 셀프 어텐션 연산을 합쳐 판별 능력을 높인 모델이다.
r개의 병렬 헤드를 사용하여, 각 헤드는 크기가 m인 벡터 h를 만든다.
rxm인 벡터 z와 출력 행렬을 점곱하여 최종 출력
트랜스포머 블록
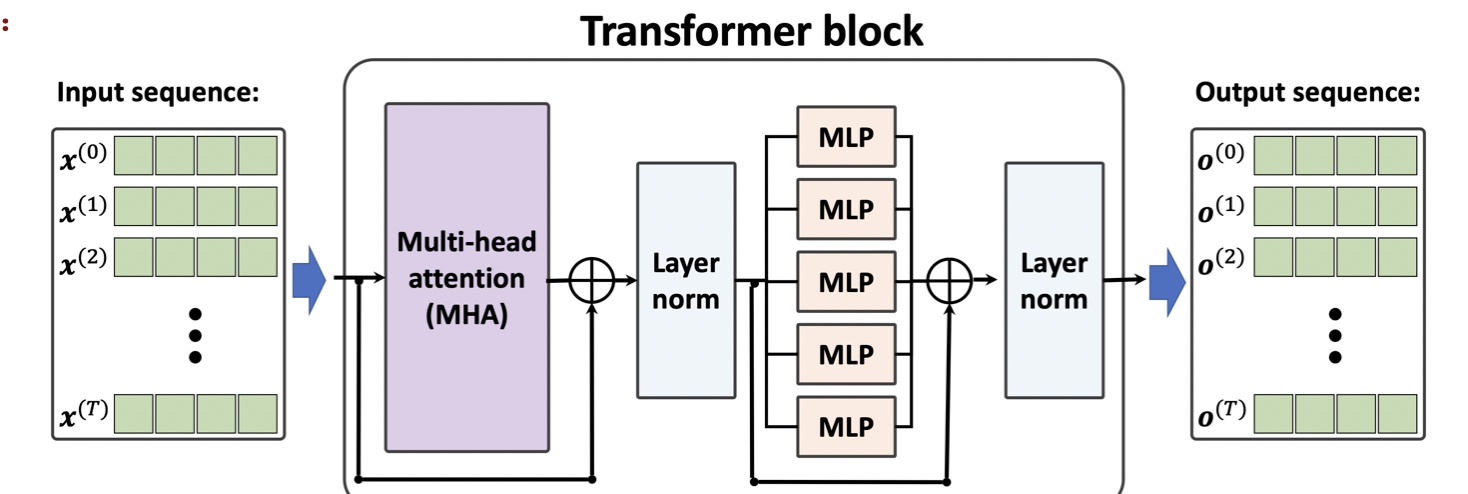
잔차 연결(residual connection) 층
잔차 연결은 층(또는 층 그룹)의 출력을 입력에 더한다.(x+layer(x))
잔차블록(residual block)
층 정규화(layer normalization)
층 정규화를 각 층에서 신경망의 입력과 활성화 출력을 정규화 또는 스케일을 조정하는 고정 방법
Progress of Transformer block
입력 시퀀스가 앞서 언급한 셀프 어텐션 메커니즘을 기반으로 하는 MHA(Multi-head attention)층으로 전달
입력 시퀀스가 잔차 연결을 통해 MHA 층의 출력에 더해진다
입력 시퀀스가 MHA층의 출력이 더해진 후 이 출력이 층 정규화를 통해 정규화
정규화된 신호가 연속된 MLP(완전 열결)층과 잔차 연결을 통과한다.
잔차 블록 출력을 다시 정규화해서 출력 시퀀스로 반환해서 시퀀스 분류나 시퀀스 생성에 사용
트랜스포머 모델 참조
머신러닝교과서with파이썬,사이킷런,텐서플로_개정3판pg.711